

多機能な PDF 編集ソフト!「ByteScout PDF Multitool」
ByteScout PDF Multitool
ByteScout PDF Multitool
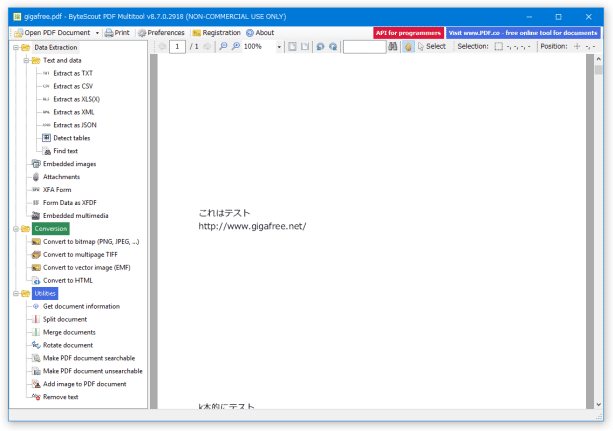
PDF を、PNG / JPEG / BMP / GIF / TIFF / EMF に変換する
- 画面左側の「Conversion」ツリー配下にある
- Convert to bitmap (PNG, JPEG, ...) - PDF を、PNG / JPEG / BMP / GIF / TIFF に変換
- Convert to multipage TIFF - PDF を、マルチページの TIFF に変換
- Convert to vector image (EMF) - PDF を、EMF ファイルに変換
- Convert to HTML - PDF を、HTML ファイルに変換
- オプション画面が表示されます。
「Convert to bitmap (PNG, JPEG, ...)」を選択していた場合は、- Convert current page - 現在のページのみを変換する
- Convert all pages - すべてのページを変換する
- Resoultion, DPI - 作成する PDF の解像度
- Output image format - 変換先のフォーマット
- JPEG quality, % - JPEG に変換する場合の画像品質
- TIFF compression - TIFF に変換する場合の圧縮アルゴリズム
- Render text - テキストを表示する
- Render images - 画像を表示する
- Render vector objects - ベクター画像を表示する
「Convert to multipage TIFF」を選択していた場合は、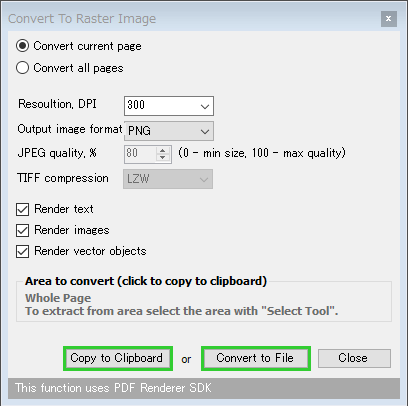
- Resoultion, DPI - 作成する PDF の解像度
- JPEG quality, % - JPEG に変換する場合の画像品質
- TIFF compression - TIFF に変換する場合の圧縮アルゴリズム
「Convert To Vector Image (EMF)」を選択していた場合は、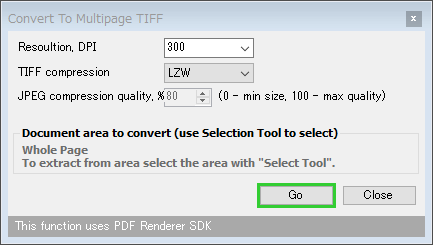
- Convert current page - 現在のページのみを変換する
- Convert all pages - すべてのページを変換する
「Convert to HTML」を選択していた場合は、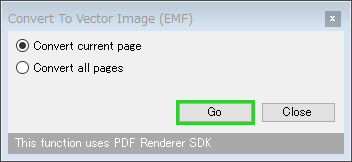
- CSS conversion - CSS でレイアウトした HTML に変換(通常はこちらを選択)
- Plain HTML conversion - プレーンな HTML に変換
- Save images - 画像の出力方法
- No - 画像を出力しない
- As Files - ファイルとして出力(通常はこれを選択)
- Embed As Data URI - URI データとして埋め込む
- Image format - 画像の出力フォーマット
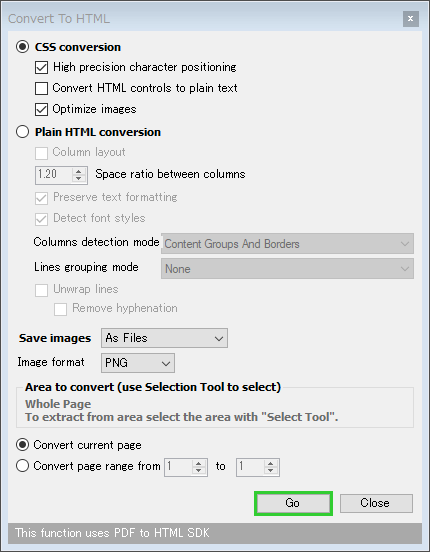
- 準備が整ったら、画面右下の「Go」ボタンをクリックします。
- 「名前を付けて保存」ダイアログが表示されます。
あとは、変換されたファイルの出力先フォルダとファイル名を指定すれば OK です。
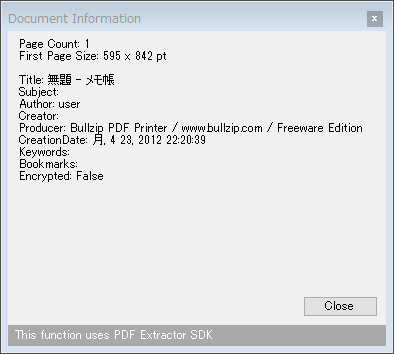
PDF のプロパティを表示する
- 画面左側の「Utilities」配下にある「Get document information」を選択します。
- すると、「Document Information」というダイアログが表示されます。
ここで、表示している PDF のプロパティを確認することができます。
PDF の分割、ページの抽出・削除
- 画面左側の「Utilities」配下にある「Split document」を選択します。
- 「Split Document」というダイアログが表示されます。
まず最初に、実行する処理の内容を下記の中から選びます。
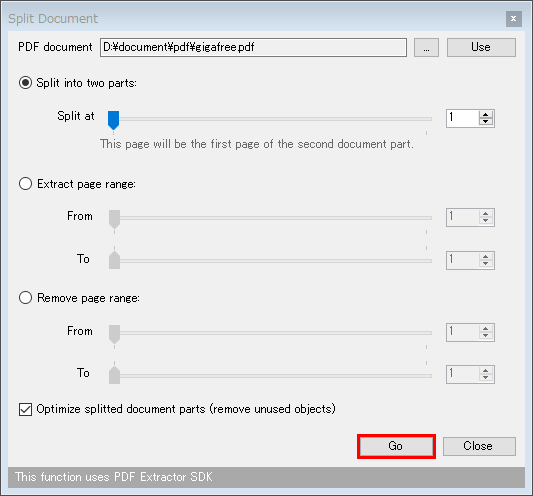
- Split into two parts - 指定したページを境にして二つに分割
- Extract page range - PDF 内から、指定した範囲のページを抽出
- Remove page range - PDF 内から、指定した範囲のページを削除
- 「Split into two parts」を選択した場合は、「Split at」欄のスライダーをドラッグし、ファイルの分割を行うページ番号を指定 → 右下の「Go」ボタンをクリックします。
「Extract page range」「Remove page range」を選択した場合は、「From」「To」欄で抽出、または削除するページの先頭番号と末尾の番号を指定 → 「右下の「Go」ボタンをクリックします。 - 「名前を付けて保存」ダイアログが立ち上がります。
あとは、編集されたファイルの保存先フォルダ&ファイル名 を指定すれば OK です。
複数の PDF を、一つに連結する
- 画面左側の「Utilities」配下にある「Merge documents」を選択します。
- 「Merge documents」という画面が表示されます。
そのまま、右上にある「Add」ボタンをクリックし、結合したい PDF ファイルを登録していきます。
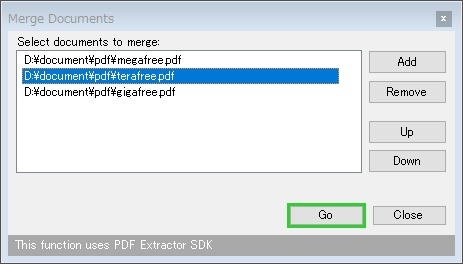
- ファイルの結合順を調整する時は、リストに登録されたファイルを選択 → 右下にある「Up」「Down」ボタンを使って並び順を調整します。
- 準備が整ったら、画面右下にある「Go」ボタンをクリックします。
- 「名前を付けて保存」ダイアログが立ち上がります。
あとは、編集されたファイルの保存先フォルダ&ファイル名 を指定すれば OK です。
PDF を回転する
- 画面左側の「Utilities」配下にある「Rotate document」を選択します。
- 「Split Document」というダイアログが表示されます。
まず、「Rotation angle」欄で、回転する角度を選択します。
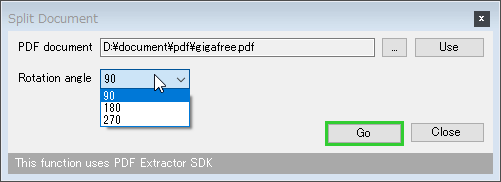
- そのまま、画面右下にある「Go」ボタンをクリックします。
- 「名前を付けて保存」ダイアログが立ち上がります。
あとは、編集されたファイルの保存先フォルダ&ファイル名 を指定すれば OK です。
PDF の内容を OCR で読み取り、読み取り結果を元に PDF を再構成する
-
テキスト検索可能な PDF に変換する
- 画面左側の「Utilities」配下にある「Make PDF document searchable」を選択します。
- 「Make PDF Document Searchable」というダイアログが表示されます。
ここで、
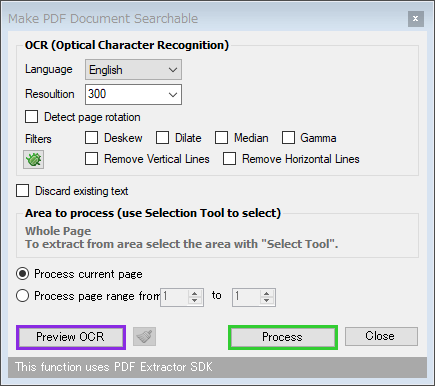
- Language - 読み取るテキストの言語
- Resoultion - テキスト読み取り時の解像度
- Discard existing text - 既存のテキストを消去する(消去されないテキストもある模様)
- Process current page※4 - 現在のページのみを OCR で再構成する
- Process page range from 〇 to △※4 - 〇ページから△ページまでを OCR で再構成する
4 PDF 自体は、全ページを含めたものが出力される。
そのうえで、どのページを “ OCR で再構成するのか(テキスト検索可能な PDF にするのか) ” ということ。 - 「名前を付けて保存」ダイアログが表示されます。
あとは、変換されたファイルの出力先フォルダ&ファイル名 を指定すれば OK です。
PDF の内容を画像に変換し、変換された画像を元に PDF を再構成する
-
テキスト検索不可能な PDF に変換する
- 画面左側の「Utilities」配下にある「Make PDF document unsearchable」を選択します。
- 「Make PDF Document Unsearchable」というダイアログが表示されます。
ここで、
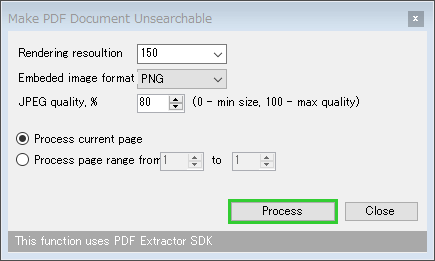
- Rendering resoultion - 再構成する PDF の解像度
- Embeded image format - 変換先画像(= PDF のページとなる画像)のフォーマット
- JPEG quality, % - JPEG に変換する際の画像品質
- Process current page - 現在のページのみを出力する
- Process page range from 〇 to △ - 〇ページから△ページまでを出力する
- 「名前を付けて保存」ダイアログが表示されます。
あとは、変換されたファイルの出力先フォルダ&ファイル名 を指定すれば OK です。
PDF 内の特定部分に、画像を合成する
- 画面左側の「Utilities」配下にある「Add image to PDF document」を選択します。
- 「Add image to PDF document」というダイアログが表示されます。
まず、右上にある
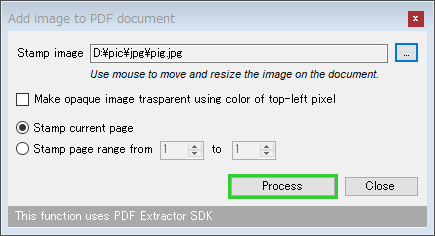
 をクリックし、PDF 内に合成する画像ファイルを選択します。
をクリックし、PDF 内に合成する画像ファイルを選択します。 - 選択した画像ファイルが、プレビュー画面上に表示されます。
これをドラッグし、合成先とする場所を指定します。
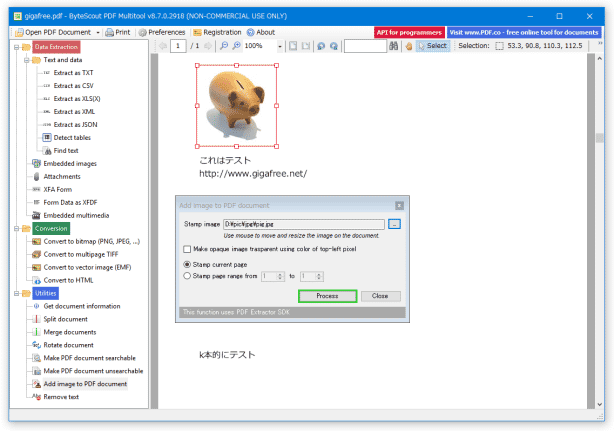
この時、画像の八方向隅にある支点をドラッグすることで、画像をリサイズすることもできたりします。 - 「Add image to PDF document」ダイアログに戻ります。
選択した画像の左上部分の色を透過させる場合は、「Make opaque image trasparent using color of top-left pixel」にチェックを入れておきます。
- 選択した画像を現在表示中のページにのみ合成する場合は、「Stamp current page」にチェックを入れます。
複数ページに渡って合成していく場合は、「Stamp page range from」にチェック → 合成を行うページの先頭番号と末尾の番号を指定します。 - 準備が整ったら、右下にある「Process」ボタンをクリックします。
- 「名前を付けて保存」ダイアログが立ち上がります。
あとは、編集されたファイルの保存先フォルダ&ファイル名 を指定すれば OK です。
PDF 内の特定領域内にあるテキストを消去する
- 画面左側の「Utilities」配下にある「Remove text」を選択します。
- 「Remove text」というダイアログが表示されます。
これはひとまず置いておき、右ペインのツールバー上にある「Select」ボタンをクリック → 消去したい部分をドラッグして囲みます。
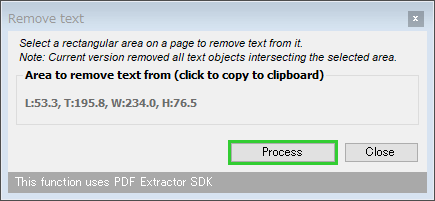
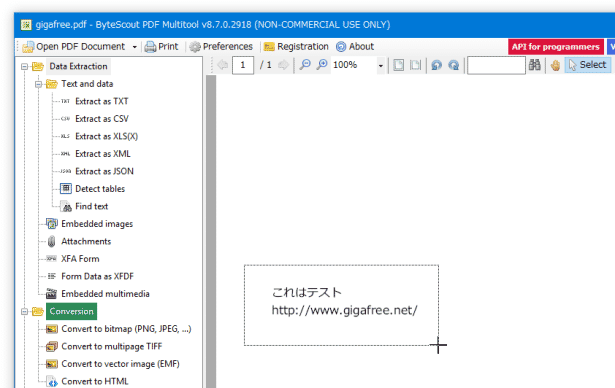
- 消したい部分を指定したら、「Remove text」ダイアログの右下にある「Process」ボタンをクリックします。
- 「名前を付けて保存」ダイアログが立ち上がります。
あとは、編集されたファイルの保存先フォルダ&ファイル名 を指定すれば OK です。


| PDF Eraser TOPへ |
アップデートなど
(旧 Twitter)
サイトの更新情報をメインに、おすすめソフトのアップデート情報なども紹介
k本的にフリーソフト別館

最近は Chrome 拡張機能や Firefox アドオンの紹介が多め...
おすすめフリーソフト





スポンサード リンク
おすすめフリーソフト
スポンサードリンク
