

画像や PDF 内の文字列を、全自動で読み取ってくれる OCR ツール!「Image Scan OCR」。
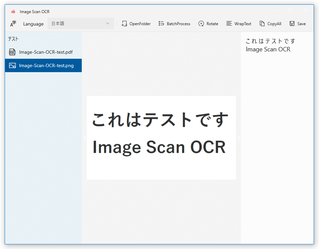
Image Scan OCR
画像や PDF 内に写っている文字列を、全自動で読み取ってくれる OCR ツール。
OCR したい画像や PDF を選択するだけで、対象ファイル内に写っている文字列をプレーンテキストとして出力することができます。
マウスドラッグで囲んだ領域内のテキストのみを読み取る機能や、ソースファイルを右に 90 度ずつ回転する機能、読み取り結果を TXT ファイルに保存する機能 などが付いています。
「Image Scan OCR」は、手軽に使える OCR ツールです。
指定した画像や PDF 内の文字列をプレーンテキストとして出力してくれる OCR ツールで、基本的に “ ソースファイルを選択するだけ ” で使えるところが最大の特徴。
目的のファイルを選択すると自動で OCR が行われるので、面倒な作業抜きにテキストの抽出を行うことができます。
(一応、マウスドラッグで囲んだ領域内の文字列のみを OCR することもできる)
OCR には Windows の OCR エンジンが採用されているため、別途ファイルを用意したりする必要がなく※1、またオフラインでも使えるようになっています。
1
ただし、読み取り可能な言語はインストールされている言語パックに依存しているので、日本語以外のテキストを読み取りたい場合は、言語パックのインストール が必要となる。
その他、ソースファイルを右に 90 度ずつ回転する機能や、読み取り結果のテキストを TXT ファイルに保存する機能 なども付いています。

使い方は以下のとおり。
使用バージョン : Image Scan OCR 1.0.7
言語パックのインストール(Windows 10)
- 日本語以外の言語も読み取りたい時は、言語パックをインストールしておきます。
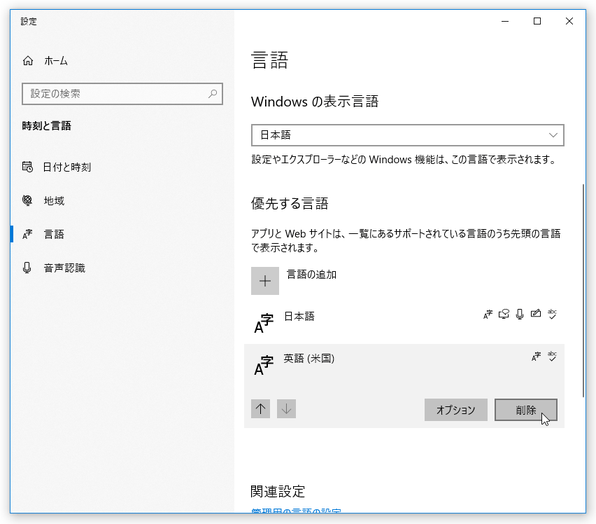
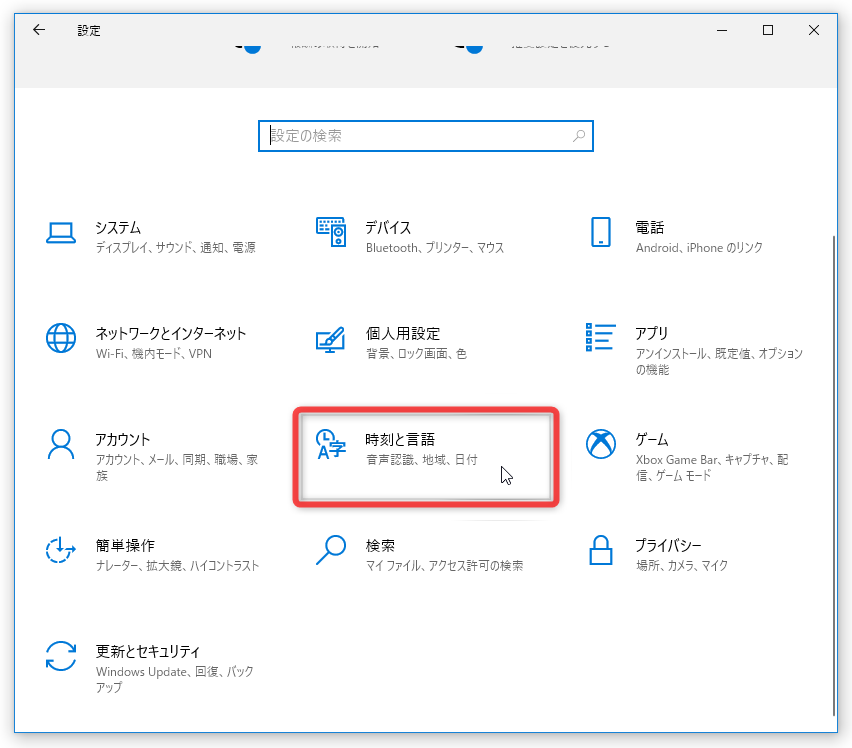
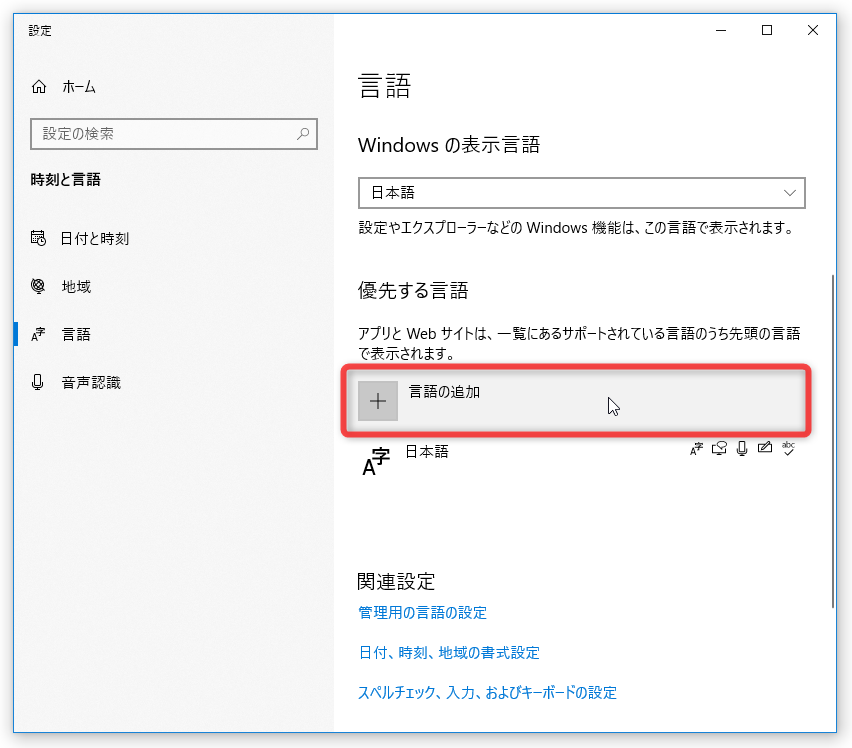
言語パックのインストールを行う場合は、「設定」アプリを開き、「時刻と言語」をクリック → 左メニュー内にある「言語」を選択します。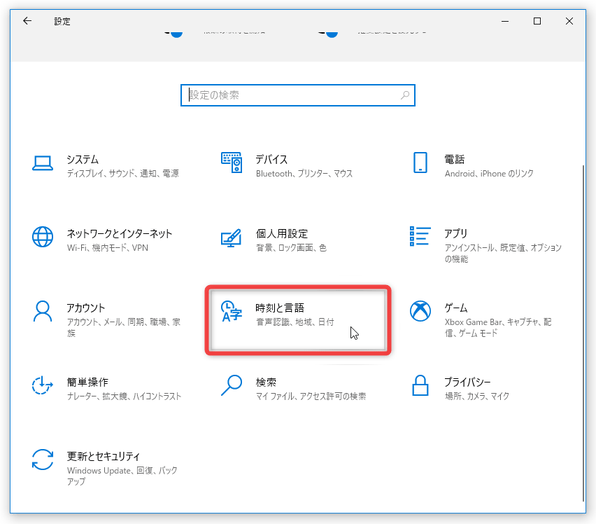
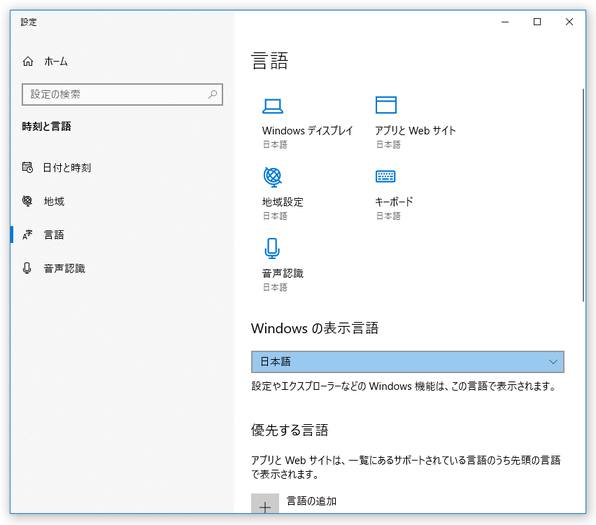
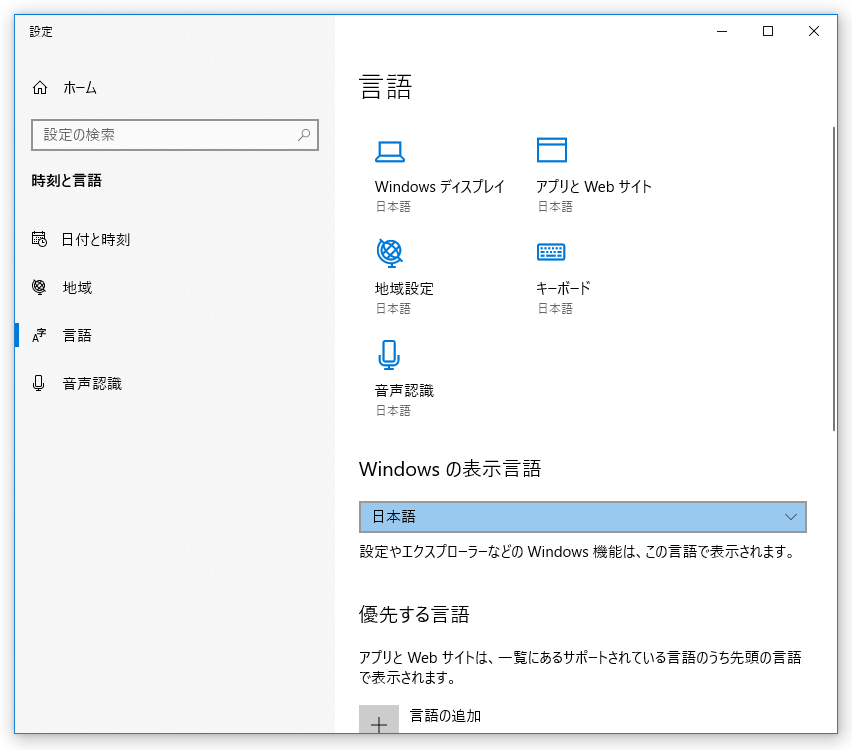
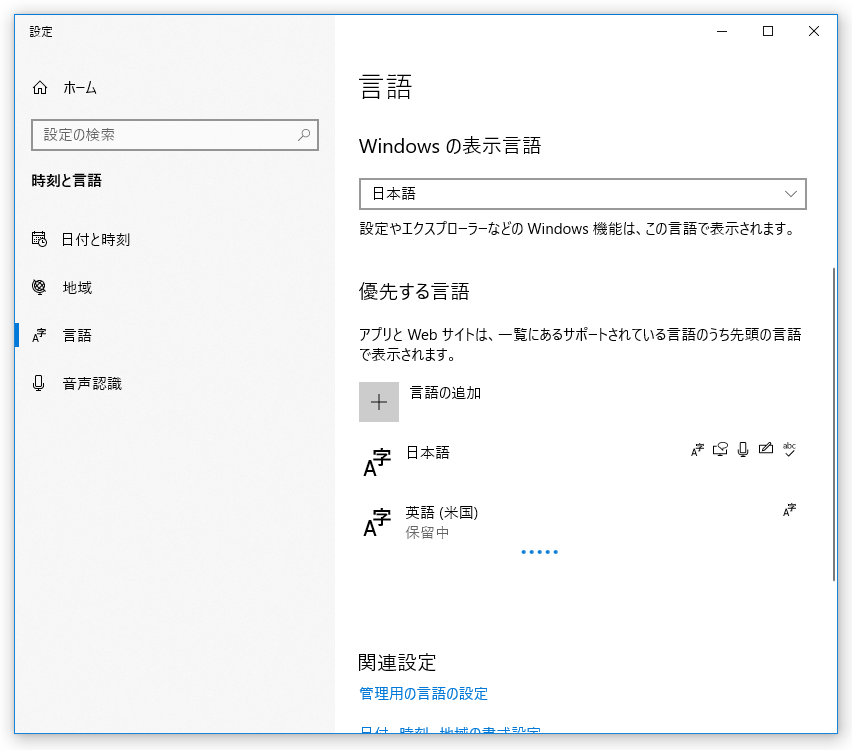
- 「言語」という画面が表示されるので、中段の「優先する言語」欄にある「言語の追加」ボタンをクリックします。
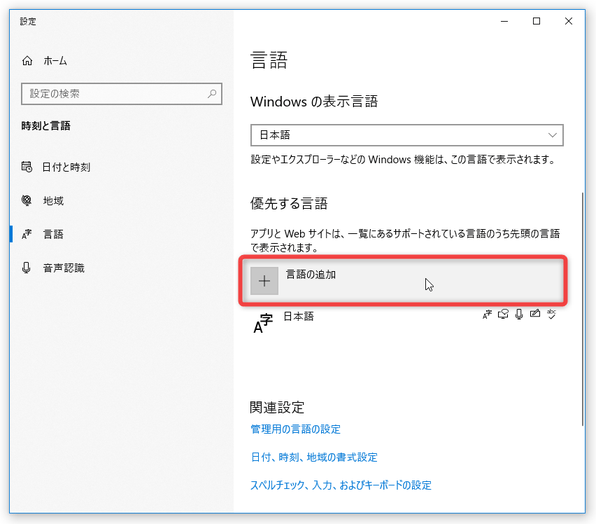
- 「インストールする言語を選択してください」というダイアログが表示されます。
ここで、インストールしたい言語を選択 → 左下の「次へ」ボタンをクリックします。
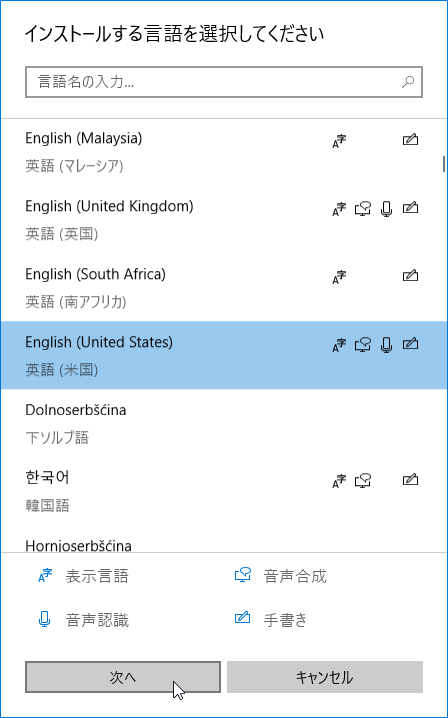
- 「言語機能のインストール」という画面が表示されます。
OCR を行うだけであれば、すべてのチェックを外して「インストール」ボタンを押して OK です。
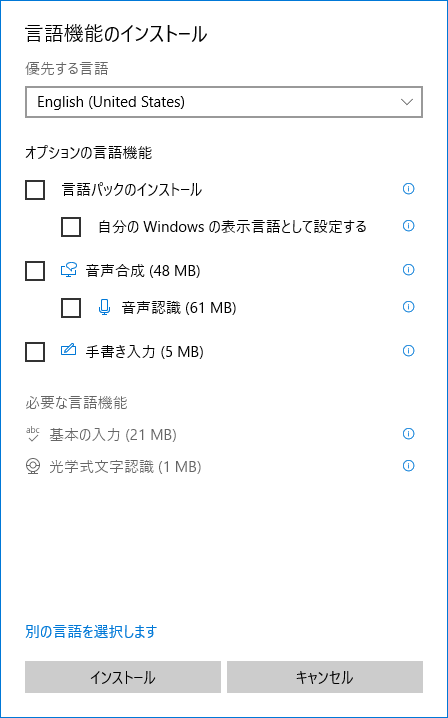
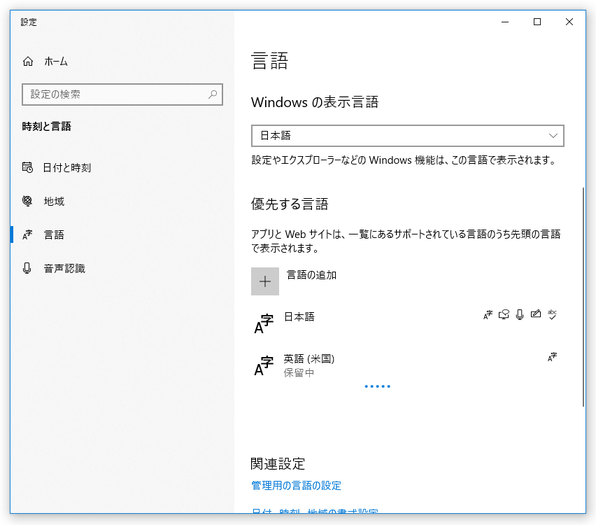
- 言語パックのインストールが行われます。
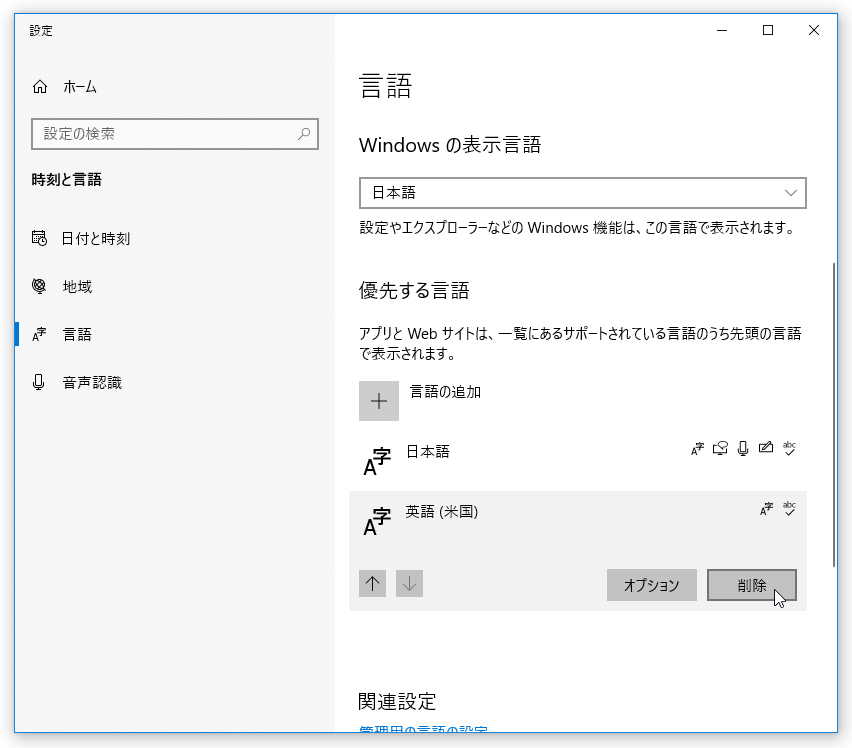
インストールした言語パックが不要になったら、目的の言語を選択 →「削除」ボタンをクリックします。
言語パックのインストール(Windows 11)
- 日本語以外の言語も読み取りたい時は、言語パックをインストールしておきます。
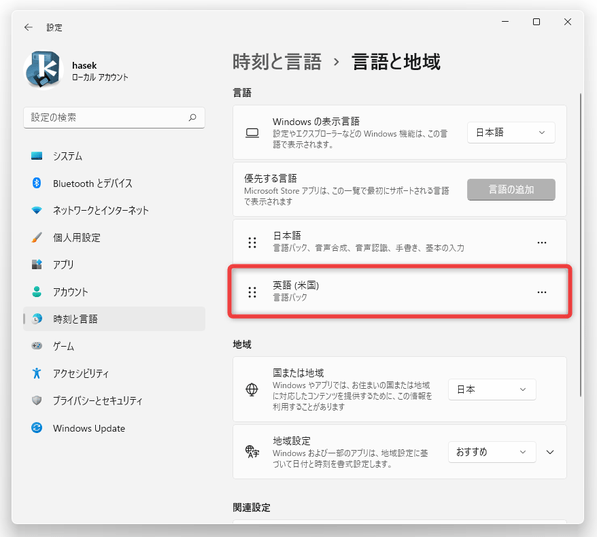
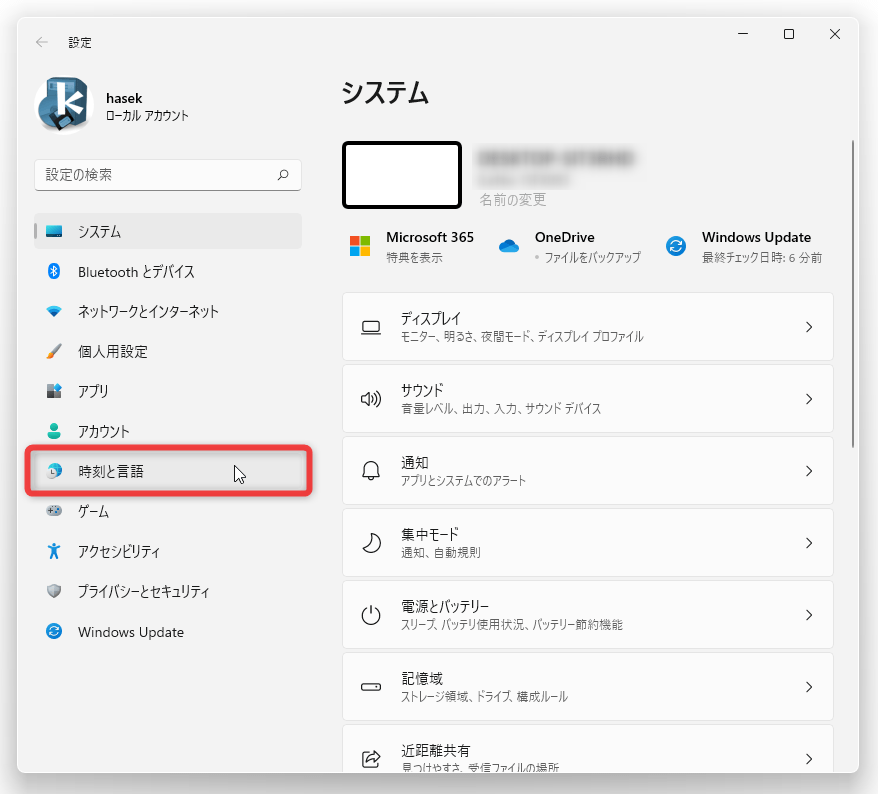
言語パックのインストールを行う場合は、「設定」アプリを開き、左メニュー内にある「時刻と言語」を選択します。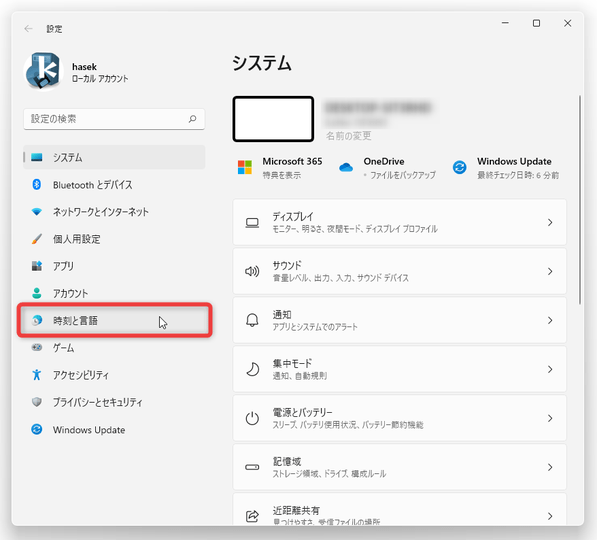
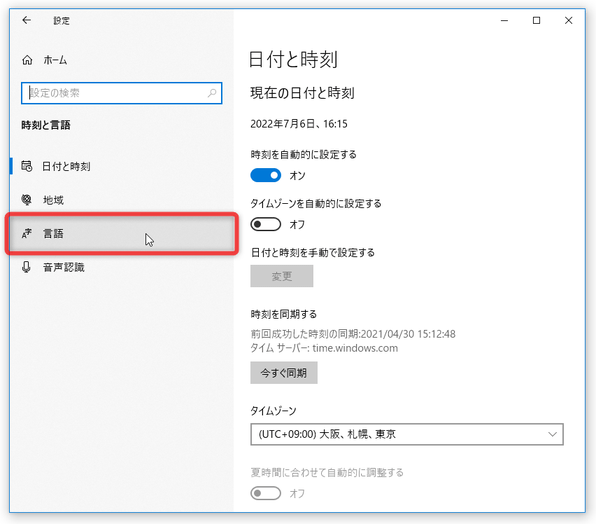
- 「時刻と言語」画面が表示されます。
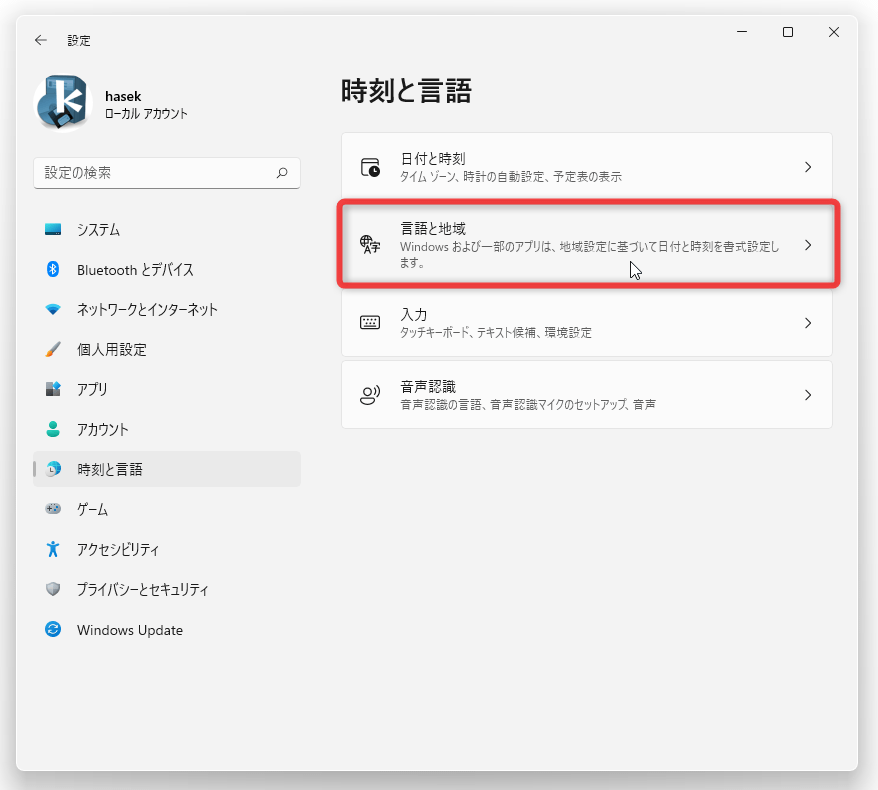
そのまま、右側にある「言語と地域」を選択します。
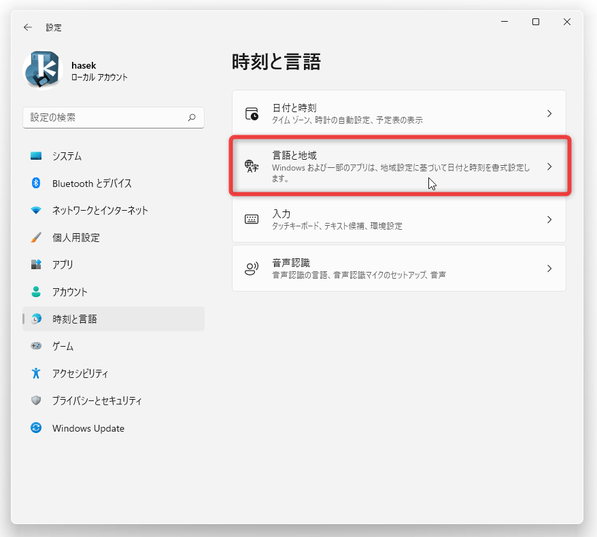
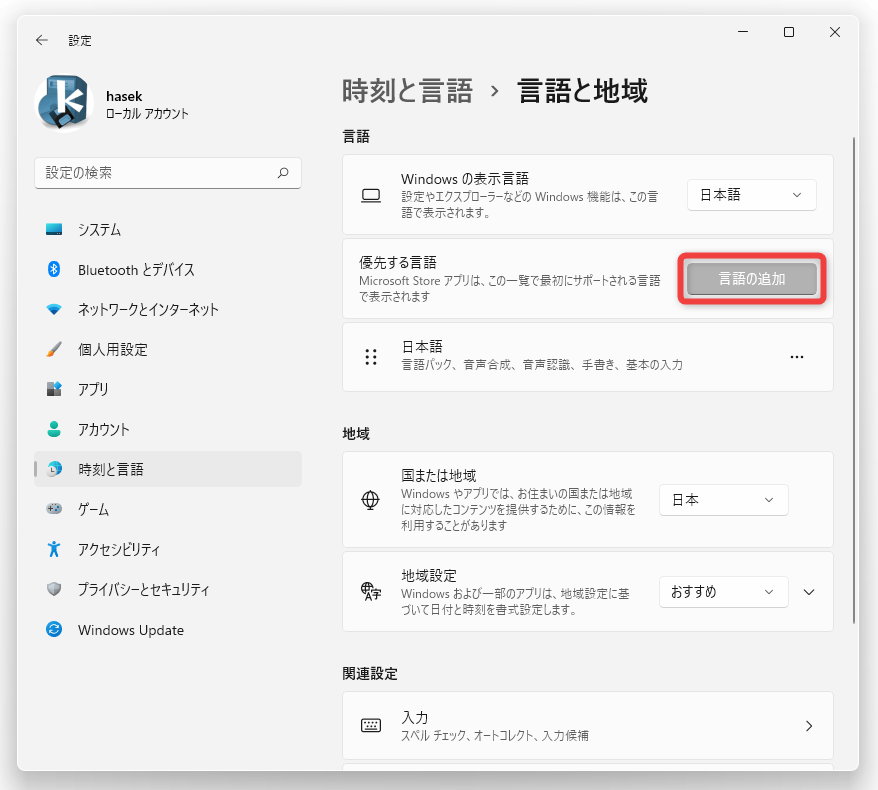
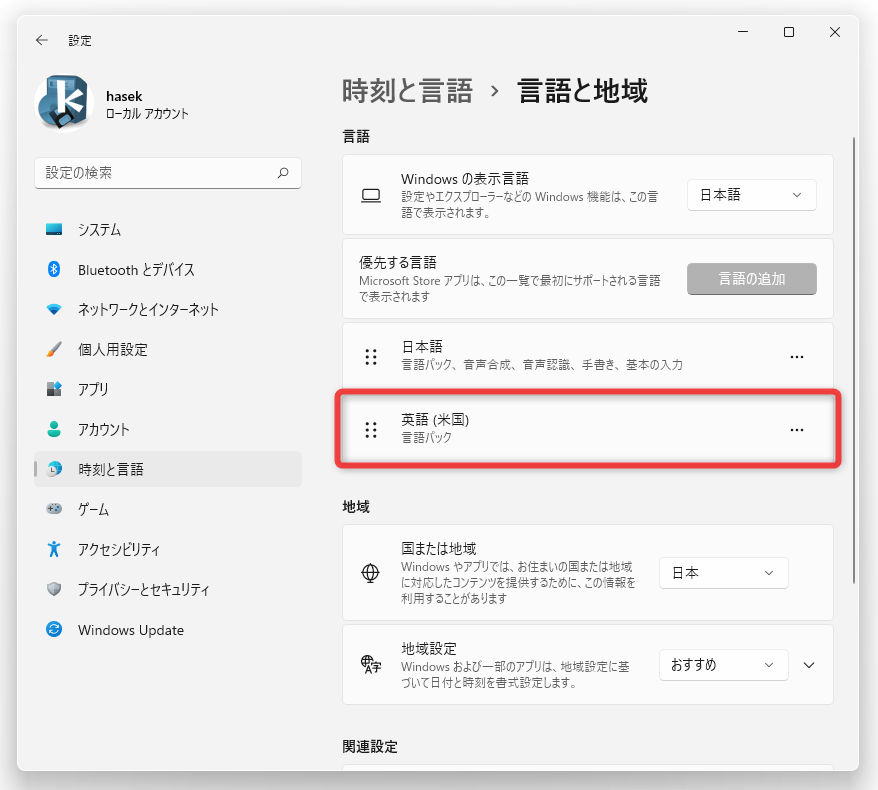
- 「言語と地域」という画面が表示されるので、右側の「優先する言語」欄内にある「言語の追加」ボタンをクリックします。
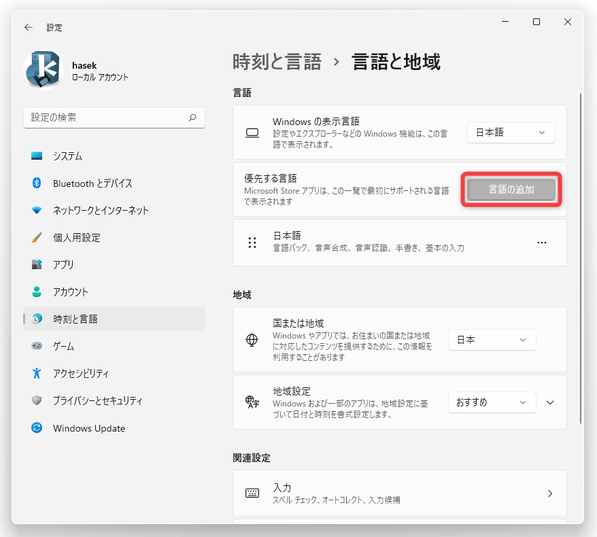
- 「インストールする言語を選択してください」というダイアログが表示されます。
ここで、インストールしたい言語を選択 → 左下の「次へ」ボタンをクリックします。
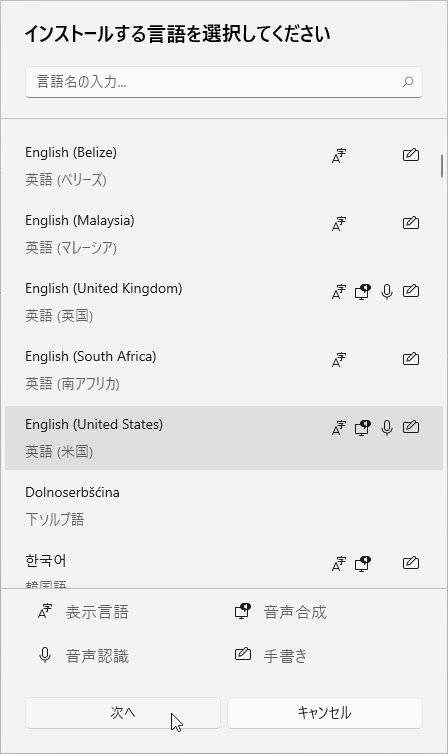
- 「言語機能のインストール」という画面が表示されます。
OCR を行うだけであれば、すべてのチェックを外して「インストール」ボタンを押して OK です。
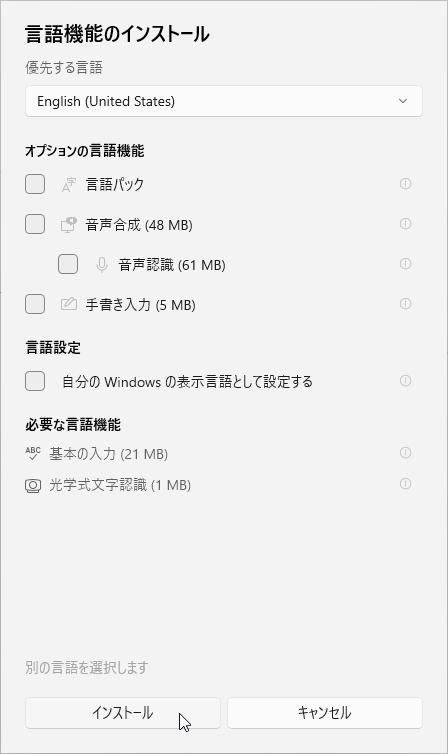
- 言語パックのインストールが行われました。
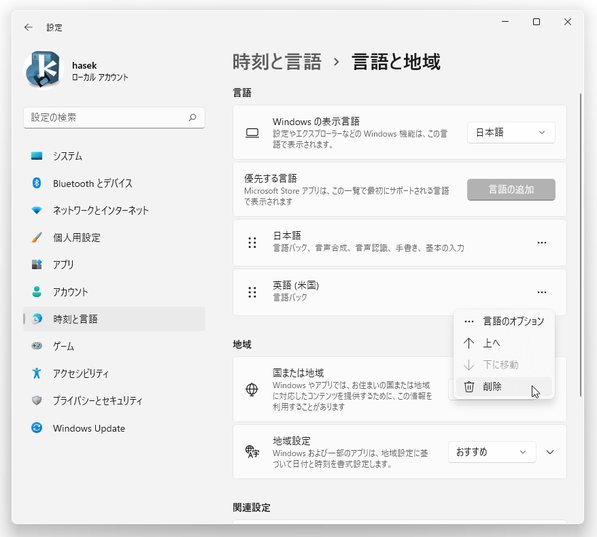
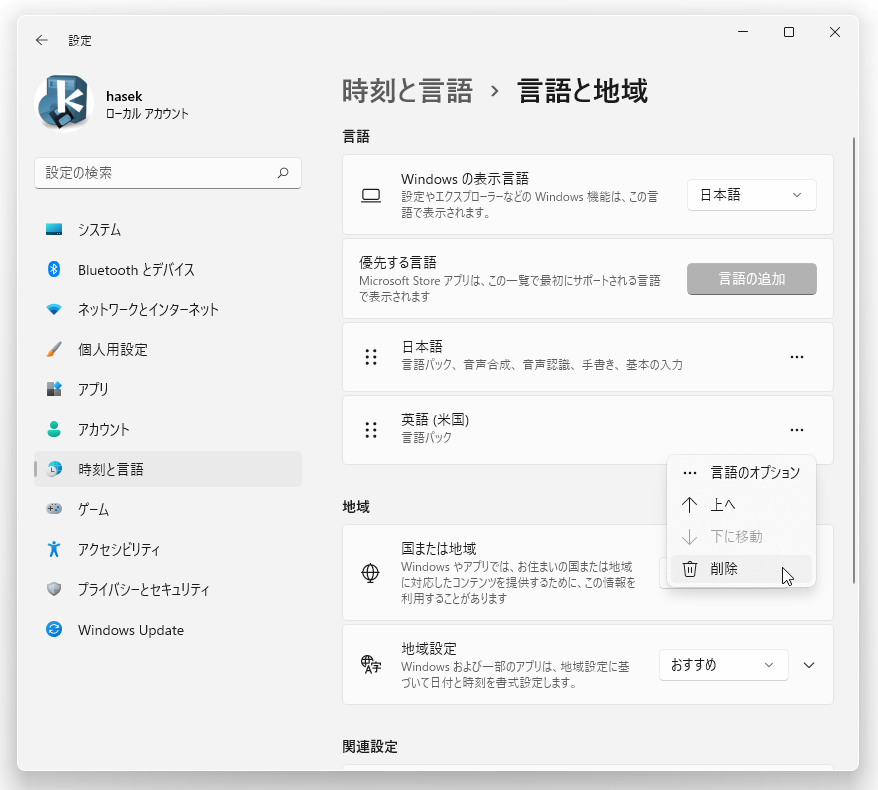
インストールした言語パックが不要になったら、目的言語の右側にあるメニューボタンをクリック →「削除」を選択します。
基本的な使い方
- スタートメニュー等から「Image Scan OCR」を実行します。
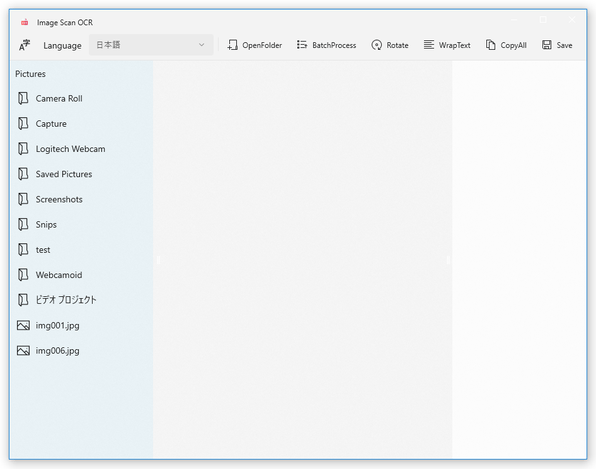
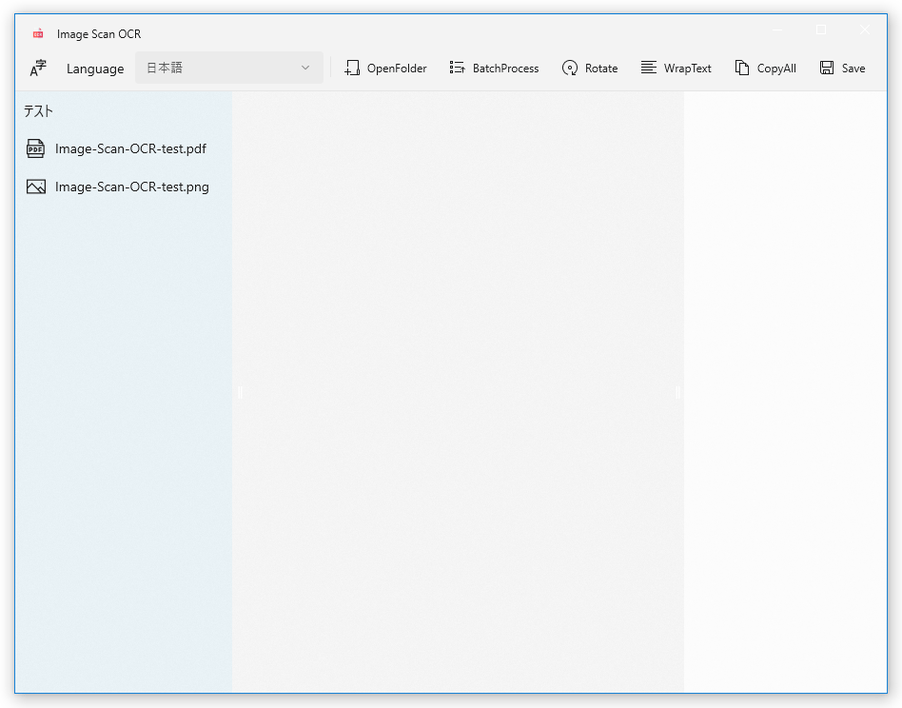
- メイン画面が表示されます。
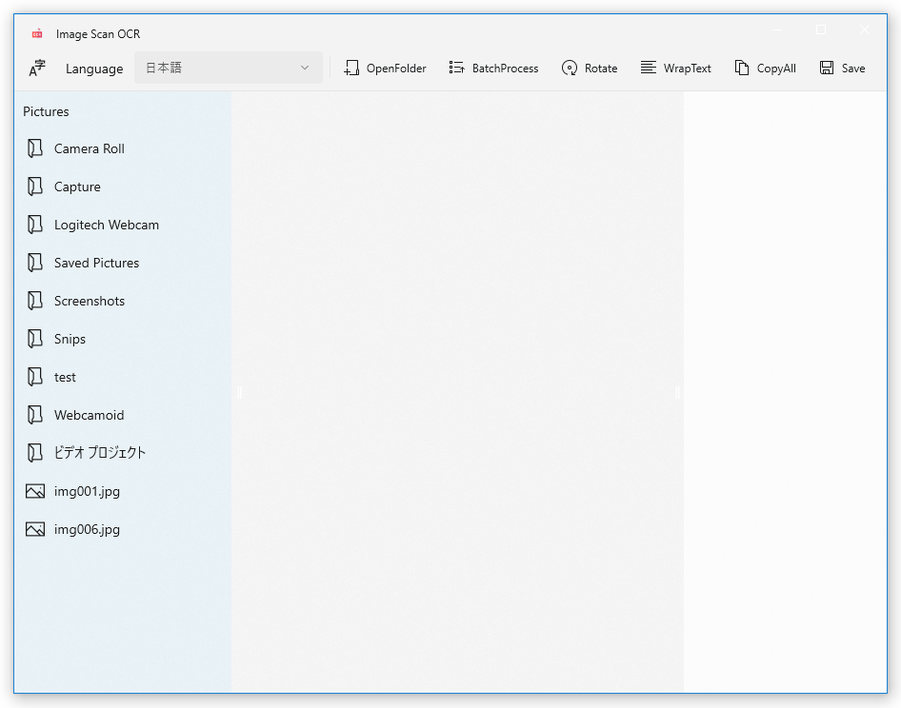
おそらく、デフォルトでは「ピクチャ」フォルダが選択された状態になっています。
OCR したい画像や PDF が他のフォルダ内に入っている時は、ツールバー上の「OpenFolder」ボタンを押して目的のフォルダを選択します。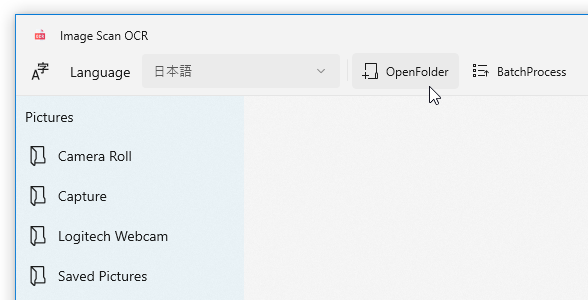
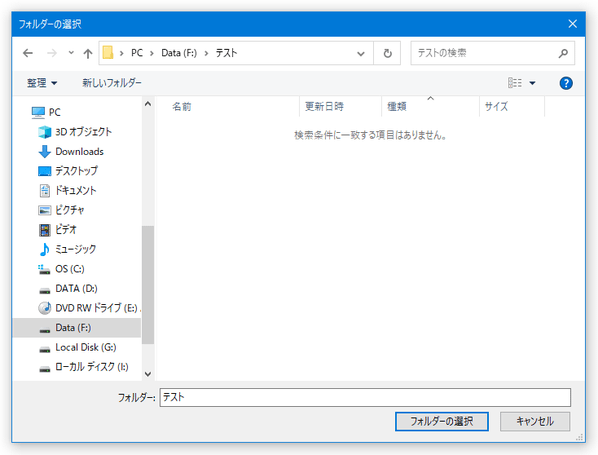
- 画面左側に、選択したフォルダ内に入っている画像や PDF がリスト表示されます。
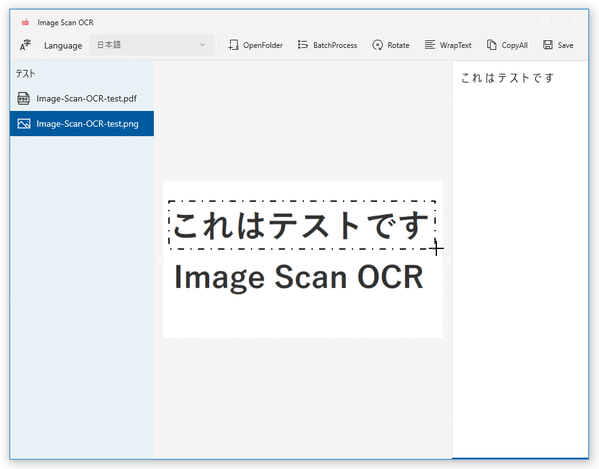
この中から、 OCR したいファイルを選択します。
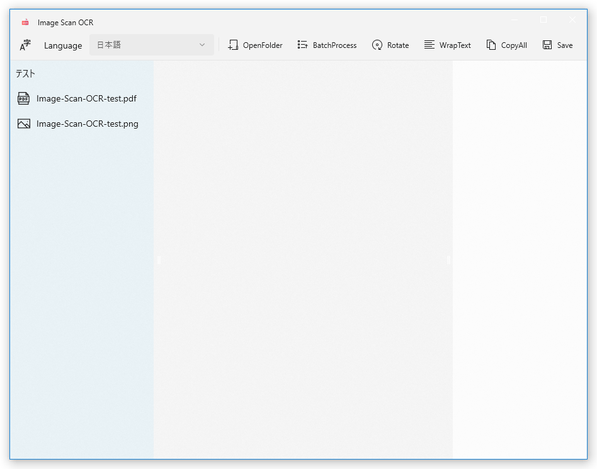
尚、読み取り対象のファイルが PDF である場合、ファイルを選択 → 子ツリーが表示されるので、それをクリックします。また、日本語以外のテキストを読み取りたい時は、左上の「Language」欄にあるプルダウンメニューをクリック → 読み取り対象の言語を選択します。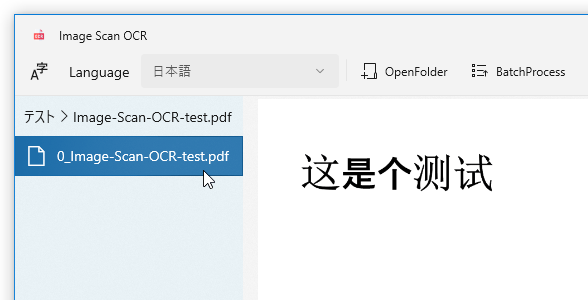
(事前に言語パックをインストールしている必要があります)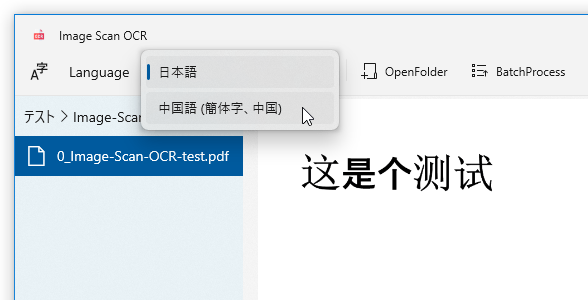
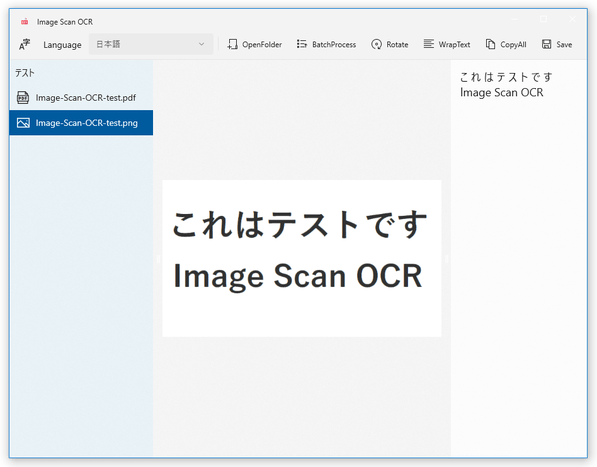
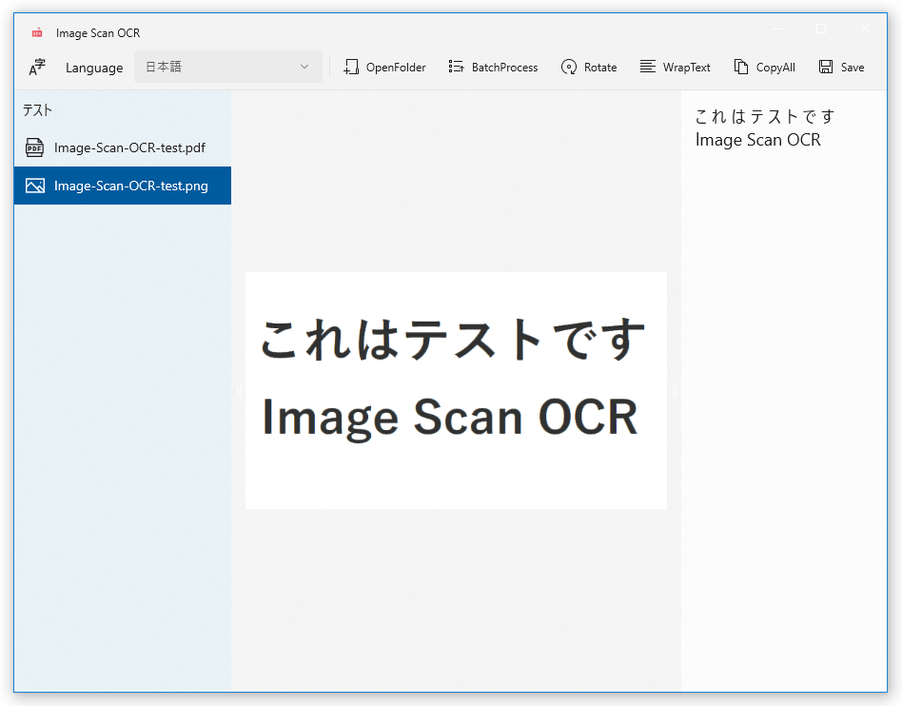
- 選択したファイルの内容が画面中央にプレビュー表示され、右側の欄に読み取り結果のテキストが表示されます。
あとは、読み取り結果のテキストをコピーすれば OK です。
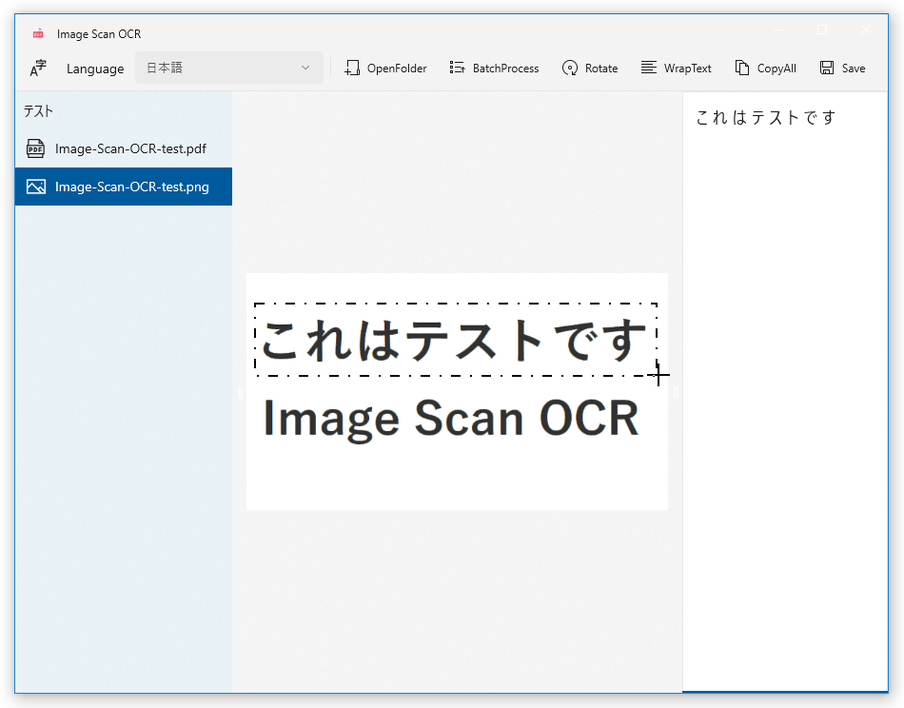
(ここでテキスト編集を行うこともできます)この時、ツールバー上にある「Rotate」ボタンを押すことにより、ソースファイルを右に 90 度ずつ回転させることもできます。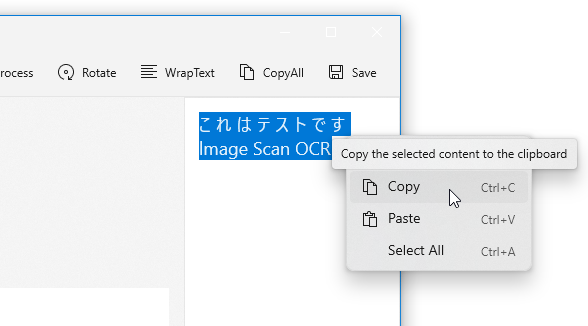 また、プレビュー画像内に写っている文字列をマウスドラッグで囲むことで、選択領域内のテキストのみを OCR することも可能となっています。
また、プレビュー画像内に写っている文字列をマウスドラッグで囲むことで、選択領域内のテキストのみを OCR することも可能となっています。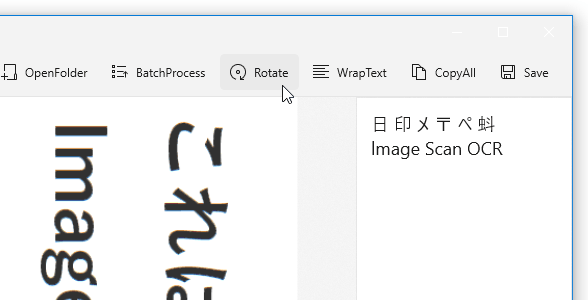
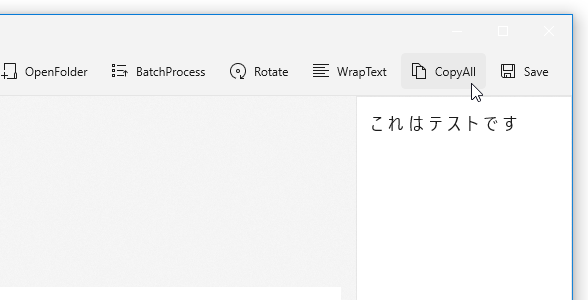
- ちなみに、ツールバー上の「CopyAll」ボタンを押すことにより、読み取り結果のテキストをクリップボードにコピーすることもできます。
加えて、ツールバーの右端にある「Save」ボタンを押すことで、読み取り結果のテキストを TXT ファイルに保存することも可能となっています。

| Image Scan OCR TOPへ |
アップデートなど
(旧 Twitter)
サイトの更新情報をメインに、おすすめソフトのアップデート情報なども紹介
k本的にフリーソフト別館

最近は Chrome 拡張機能や Firefox アドオンの紹介が多め...
おすすめフリーソフト






おすすめフリーソフト
スポンサードリンク
